
Simple and Multi Linear Regression Model of Verbs in Quran
Vol.08No.01(2018), Article ID:83082,10 pages
10.4236/ajcm.2018.81006
Abdelkrim El Mouatasim
Faculty of Polydisciplinary Ouarzazate (FPO), Ibn Zohr University, Ouarzazate, Morocco
Copyright © 2018 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: February 17, 2018; Accepted: March 13, 2018; Published: March 16, 2018
ABSTRACT
This paper mainly presented a good simple and multi-linear regression model of verbs in the Quran book. This model, gives an analysis for the influence to frequency of words with the form (―un, ون---) made by the frequency of plural present verbs (t―un, ت---ون) or (y―un, ي---ون), and models, and the relationship between independent variables and dependent variable by fitting a linear equation to the observed data with simple linear regression model. The matlab function is used for finding the parameters of the linear regression model and plotting the fits. The results show that the parameters of the model are one vector (1, 1) and mean of dataset is (6, 7). Its corresponding to the verb with input is frequency of the verb they enter and the frequency of enter (yadkolun دخلون ، يدخلون dakilun), also other 17 points exist in the line and in the dataset of 387 verbs and their derivate verbs in Quran. The name of Allah (الله) showed when we use tree variables and plot it in 3D with option “Show Text” for a multi regression model.
Keywords:
Linear Regression, Text Mining, Quran Statistics, Matlab, Arabic Grammar, Optimization, Computation Linguistics

1. Introduction
The scripture of the Quran has been subjected to various intense mathematically based studies to reveal the protection mechanisms embedded in the composition of the Quran and to provide evidence of its credibility, authenticity and divinity see for instance [1] [2] .
Therefore, the development of the mathematical theory has been highly motivated and driven by the categorical recognition of the author that Allah may have embedded varying mathematical algorithms, equations and regression models for protecting the Quran, as well as to prove its divinity and to emphatically exclude any human influence on the manufacture of the Quran. Because Allah promises that the Quran will always be preserved and protected from any corruption such as addition or deletion or relocation of any of its verses from chapter to another. Therefore, unveiling any of these algorithms would help unlock many of the Quranic secrets, particularly those related to the Quran’s primary parameters like words and verbs as well as how the Quran’s design is related to the fit of linear regression.
Furthermore, this work is set to statistically and numerically validate and authenticate the first drawing of the Quran (Uthmanic manuscript) related statistics such as the total number of words and verbs of the Quran.
Regression analysis describes the relationship between a dependent variable and several independent variables.
Regression analysis describes the relationship between a dependent variable and several independent variables, for the estimation of the parameters model see for instance [3] [4] .
This paper is organized as follows: in Section 2, we give the initiation of linear regression; linear regression model in Quran with numerical results is given in Section 3.
2. Linear Regression Models
2.1. Simple Linear Regression
Regression analysis is a statistical technique for estimating the relationship among variables which have reason and result relation. Main focus of univariate regression is analyses the relationship between a dependent variables and one independent variable Y and formulates the linear relation equation between dependent and independent variable.
The simple linear regression model is the simplest regression model in which we have only one predictor X.
This model, which is common in practice, is written as
where
- are the values of the response and predictor variables in the trial, respectively;
- The unknown parameters: a is called the intercept, and b is the slope of the line;
- is usually assumed to be iid (error) from specially for inference purposes (see for instance [5] ).
Then estimates of simple linear model’s parameters should be obtained accordingly, using some method like the ordinary least squares method, which relies on minimizing the sum of square of errors .
For the simple linear regression model the ordinary least squares estimations of a and b are
and
where and are the mean of the variable X and the variable Y respectively.
The goodness of fit is defined as
.
2.2. Matrix Form of Multiple Regression
Regression models with one dependent variable and more than one independent variable are called multi-linear regression (see for instance [6] ).
Multivariate regression analysis model is formulated as in the following:
where
- Y is the dependent variable,
- is the independent variables,
- is the parameters,
- ε is the error.
The assumptions of multi-linear regression analysis are normal distribution, linearity, freedom extreme values and having no multiple ties between independent variables [6] .
The linear model can be written as
where
- is the vector of observations on the dependent variable,
.
- is the matrix consisting of a column of ones and p column vectors of the observations on the independent variables, the form of X is
- is the vector of parameters to be estimated,
.
- is the vector of random errors,
.
The vector is a vector of unknown constants to be estimated from the data by .
The normal equations [7] are written as
.
If has an inverse, then the unique solution of normal equations given by
.
The vector of estimated means of the dependent variable Y for the values of the independent variables in the dataset is computed as
.
However, to express as a linear function of Y. Thus,
.
3. Model and Numerical Results
3.1. Definition of Variables
In this section we conceder the following integer variables:
- the frequency of plural present verbs with a form (y―un, ي---ون) or there inverse (ly―un, لي---ون);
- the frequency of plural present verbs with a form (t―un, ت---ون) or there inverse (lt―un, لت---ون);
- the frequency of the verbs in the above form without (t,ت) or (y,ي ).
We use the software of Quran statistics [8] let for determined the set of triple .
Let is the sum of frequency of all above derivative verbs with same form.
However, the dataset are given in Table 1.
3.2. Simple Linear Regression Model of Verbs
Since are not a frequency of plural present verbs [9] then, we let a dependent variable and Y an independent variable for simple linear regression model. However, the simple linear regression model of verbs is:
where a and b are the parameters of the model.
For estimate the parameters a and b, calculate the coefficient of correlation R, plotting a fit and test hypothesis of simple linear regression model we used the following matlab codes:
[r, m, b] = regression (X, Y);
plotregression (X, Y);
fitlm (X, Y);

Table 1. Dataset of words in Quran.
The results of regression m function is given as the parameters and the coefficient of correlation , see also Figure 1. And the results of test hypotheses by fitlm. m function are:

is frequency of verbs of enter (yadkolun دخلون ، يدخلون dakilun).
Also there exist 17 point in dataset in the line fit their equation is , when we use the commend find ( ) there indexes in dataset are:

For more information’s about the correspondence of this points in the dataset see Table 2 see for instance [10] [11] .3.3. Multi Linear Regression Model of VerbsFor multi linear regression model of verbs: where and are the parameters of the model.For estimate the parameters and , and test hypothesis of multi linear regression model we used the following matlab code:

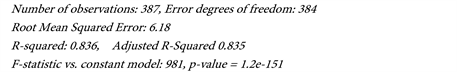
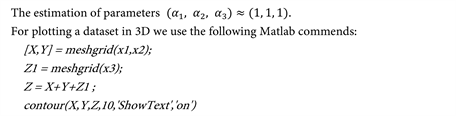
Number of observations: 387, Error degrees of freedom: 384Root Mean Squared Error: 6.18R-squared: 0.836, Adjusted R-Squared 0.835F-statistic vs. constant model: 981, p-value = 1.2e−151Also in the Figure 2, we show the name of Allah in Arabic الله.

Figure 1. Plotting dataset in 2D.

Figure 2. Plotting dataset in 3D.
Table 2. The verbs in line fit.
4. Conclusions and Future Work
The present dataset in this paper fined in Quran gives a good simple and multi linear regression model between the frequency of verbs with a form (―un, ون---) made by the frequency of plural present verbs (t―un, ت---ون) or (y―un, ي---ون) and there inverses.
The results show that the parameters of the model are ones vector (1,1) and mean of dataset is (6, 7). It corresponds to the verb point enter (yadkolun دخلون ، يدخلون dakilun), also other 17 points exist in the line and in the dataset of 387 verbs and their derivate verbs in Quran. The name of Allah (الله) showed when we use tree variables and plot it in 3D with option “Show Text”.
For future work, the estimation parameter of this dataset will be done by using norm and sub-gradient method, and comparing this model in other drawing of the Quran.
Acknowledgements
The author thanks Allah for this miracle dataset in Quran. Also we are indebted to the anonymous reviewers and editors of AJCM for many suggestions and stimulating comments to improve the original manuscript.
Cite this paper
El Mouatasim, A. (2018) Simple and Multi Linear Regression Model of Verbs in Quran. American Journal of Computational Mathematics, 8, 68-77. https://doi.org/10.4236/ajcm.2018.81006
References
- 1. Al-Faqih, K.M. (2017) A Mathematical Phenomenon in the Quran of Earth-Shattering Proportions: A Quranic Theory Based on Gematria Determining Quran Primary Statistics (Words, Verses, Chapters) and Revealing Its Fascinating Connection with the Golden Ratio. Journal of Arts and Humanities, 6, 52-73. https://doi.org/10.18533/journal.v6i6.1192
- 2. Al-Kaheel, A. (2017) http://www.kaheel7.com/ar/index.php/1/1690-2014-07-03-19-11-02
- 3. El Mouatasim, A. and Al-Hossain, A. (2009) Reduced Gradient Method for Minimax Estimation of a Bounded Poisson Mean. Journal of Statistics: Advances in Theory and Applications, 2, 183-197.
- 4. El Mouatasim, A. and Wakrim, M. (2015) Control Subgradient Algorithm for Image Regularization. Journal of Signal, Image and Video Processing (SViP), 9, 275-283. https://doi.org/10.1007/s11760-015-0815-z
- 5. Smadi, A.A. and Abu-Afouna, N.H. (2012) On Least Squares Estimation in a Simple Linear Regression Model with Periodically Correlated Errors: A Cautionary Note. Austrian Journal of Statistics, 41, 211-226. https://doi.org/10.17713/ajs.v41i3.175
- 6. Uyanik, G.K. (2013) A Study on Multiple Linear Regression Analysis. Procedia-Social and Behavioral Sciences, 106, 234-240. https://doi.org/10.1016/j.sbspro.2013.12.027
- 7. Rawlings, J.O., Pantula, S.G. and Dickey, D.A. (1998) Applied Regression Analysis: A Research Tool. 2nd Edition, Springer, Berlin. https://doi.org/10.1007/b98890
- 8. Al-Kaheel, A. (2006) Ishraqat al-Raqam Sab`a fial-Qur’an al-Karim. Dubai International Holy Quran Award, Dubai.
- 9. Al-Hakkak, G. (2016) Arabic Verbs. Arabic Online for English Speakers.
- 10. https://www.almaany.com/ar/dict/ar-en/
- 11. https://translate.google.com/
上一篇:On the Location of Zeros of Po 下一篇:Solving Stiff Reaction-Diffusi
最新文章NEWS
- Auto-Bäcklund Transformation and Extended Tanh-Function Methods to Solve the Time-Dependent Coeffici
- A Third-Order Scheme for Numerical Fluxes to Guarantee Non-Negative Coefficients for Advection-Diffu
- Conjugate Effects of Radiation and Joule Heating on Magnetohydrodynamic Free Convection Flow along a
- An O(k<sup>2</sup>+kh<sup>2</sup>+h<sup>2</sup>) Accurate Two-le
- On the Location of Zeros of Polynomials
- Peristaltic Pumping of a Conducting Sisko Fluid through Porous Medium with Heat and Mass Transfer
- An Accurate Numerical Integrator for the Solution of Black Scholes Financial Model Equation
- Simulation of Time-Dependent Schrödinger Equation in the Position and Momentum Domains
推荐期刊Tui Jian
- Chinese Journal of Integrative Medicine
- Journal of Genetics and Genomics
- Journal of Bionic Engineering
- Pedosphere
- Chinese Journal of Structural Chemistry
- Nuclear Science and Techniques
- 《传媒》
- 《中学生报》教研周刊
热点文章HOT
- Asymptotic Solutions for the Fifth Order Critically Damped Nonlinear Systems in the Case for Small E
- Partial Fraction Decomposition by Repeated Synthetic Division
- Higher-Order Numerical Solution of Two-Dimensional Coupled Burgers’ Equations
- Group Method Analysis of MHD Mixed Convective Flow Past on a Moving Curved Surface with Suction
- Simple and Multi Linear Regression Model of Verbs in Quran
- Conjugate Effects of Radiation and Joule Heating on Magnetohydrodynamic Free Convection Flow along a
- Peristaltic Pumping of a Conducting Sisko Fluid through Porous Medium with Heat and Mass Transfer
- An O(k<sup>2</sup>+kh<sup>2</sup>+h<sup>2</sup>) Accurate Two-le